- RBD 是 Ceph 分布式存储系统中提供的块存储服务
- 该篇主要针对 RBD 中的整体架构以及 IO 流程进行介绍
- 针对 librbd 中提供的接口进行简单介绍,后续将在此基础上进行实战
Ceph RBD
RBD:RADOS Block Devices. Ceph block devices are thin-provisioned, resizable and store data striped over multiple OSDs in a Ceph cluster.
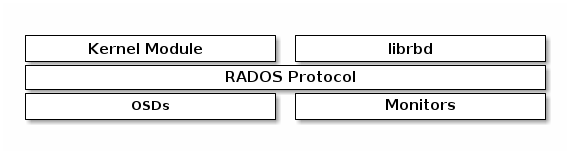
整体介绍
Ceph RBD 模块主要提供了两种对外接口:
- 一种是基于 librados 的用户态接口库 librbd,支持 C/C++ 接口以及 Python 等高级语言的绑定;
- 另外一种是通过 kernel Module 的方式(一个叫 krbd 的内核模块),通过用户态的 rbd 命令行工具,将 RBD 块设备映射为本地的一个块设备文件。
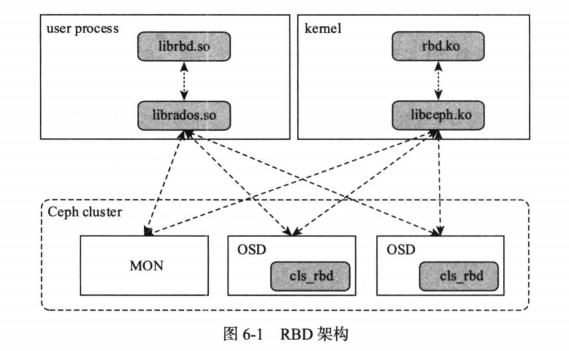
- RDB 的块设备由于元数据信息少而且访问不频繁,故 RBD 在 Ceph 集群中不需要单独的守护进程讲元数据加载到内存进行元数据访问加速,所有的元数据和数据操作直接与集群中的 Monitor 服务和 OSD 服务进行交互。
RBD IO 流
- RBD 模块 IO 流图

几个重要的存储组织
- Pool:存储资源池。IO 之前,需要先创建一个存储池,存储池统一地对逻辑存储单元进行管理,并对其进行初始化。同时指定一个 Pool 中的 PG 数量。是 Ceph 存储数据时的逻辑分区,类似于 HDFS 中的 namespace
1 | ceph osd pool create rbd 32 |
RBD:块设备镜像。在创建好 Pool 的基础之上,对应的创建块设备镜像并和存储池进行映射绑定
Object:按照数据切片的大小,将所有数据切片为一个个对象,进行相应的对象存储操作。其中 Key 需要根据序号进行生成从而进行区分。
1 | rbd create --size {megabytes} {pool-name}/{image-name} |
- PG:Placement Group,用于放置标准大小的 Object 的载体。其数量的计算公式:
Total PGs = (Total_number_of_OSD * 100) / max_replication_count再对结果向上取 2 的 N 次方作为最终的数量。PG 同时作为数据均衡和迁移的最小单位,PG 也有相应的主从之分。 - OSD:OSD 是负责物理存储的进程,也可以理解为最终的对象存储节点。一般情况下,一块磁盘启动一个 OSD 进程,一组 PG (多副本)分布在不同的 OSD 上。
IO流程
- 客户端创建对应的存储池 Pool,指定相应的 PG 个数以及 PGP 个数(用于 PG 中的数据均衡)
- 创建 pool/image rbd设备进行挂载
- 用户写入的数据进行切块,每个块有默认大小,并且每个块都有一个 Key,Key 就是 object+序号
- 将每个 object 通过 pg 进行副本位置的分配
- PG 根据 cursh 算法会寻找指定个数的 osd(主从个数),把这个 object 分别保存在这些 osd 上
- osd 上实际是把底层的 disk 进行了格式化操作,一般部署工具会将它格式化为 xfs 文件系统
- object 的存储就变成了存储一个文件 rbd0.object1.file
RBD IO 框架

客户端写数据osd过程:
- 采用的是 librbd 的形式,使用 librbd 创建一个块设备,向这个块设备中写入数据
- 在客户端本地同过调用 librados 接口,然后经过 pool,rbd,object,pg 进行层层映射(CRUSH 算法),在 PG 这一层中,可以知道数据保存在哪几个 OSD 上,这几个 OSD 分为主从的关系
- 客户端与 primary OSD 建立 SOCKET 通信,将要写入的数据传给 primary OSD,由 primary OSD 再将数据发送给其他 replica OSD 数据节点。
librbd
- librbd 到 OSD 的数据流向如下:

模块介绍
- librbd:Librbd 是Ceph提供的块存储接口的抽象,它提供C/C++、Python等多种接口。对于C++,最主要的两个类就是RBD 和 Image。 RBD 主要负责创建、删除、克隆映像等操作,而Image 类负责映像的读写等操作。
- cls_rbd:cls_rbd是Cls的一个扩展模块,Cls允许用户自定义对象的操作接口和实现方法,为用户提供了一种比较直接的接口扩展方式。通过动态链接的形式加入 osd 中,在 osd 上直接执行。
- librados:librados 提供客户端访问 Ceph 集群的原生态统一接口。其它接口或者命令行工具都基于该动态库实现。在 librados 中实现了 Crush 算法和网络通信等公共功能,数据请求操作在 librados 计算完成后可以直接与对应的 OSD 交互进行数据传输。
- OSDC:该模块是客户端模块比较底层的模块,用于封装操作数据,计算对象的地址、发送请求和处理超时。
- OSD:部署在每一个硬盘上的 OSD 进程,主要功能是存储数据、复制数据、平衡数据、恢复数据等,与其它OSD间进行心跳检查等,并将一些变化情况上报给Ceph Monitor
- OS:操作系统,在此处则主要是 OSD 的 IO 请求下发到对应的硬盘上的文件系统,由文件系统来完成后续的 IO 操作。
librbd 详细介绍
功能模块
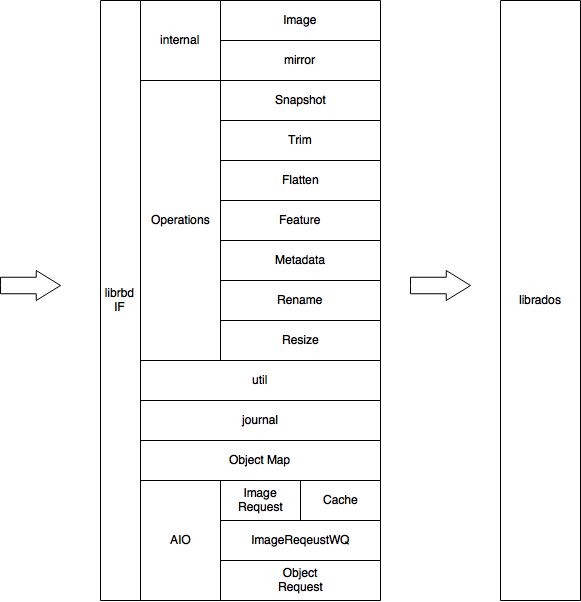
核心机制
- librbd 是一个将 block io ([off, len])转换成 rados object io ([oid, off, len])的中间层。为了支持高性能 io 处理,其内部维护了一个 io 队列,一个异步回调队列,以及对这两个队列中的请求进行处理的线程池,如下图所示。
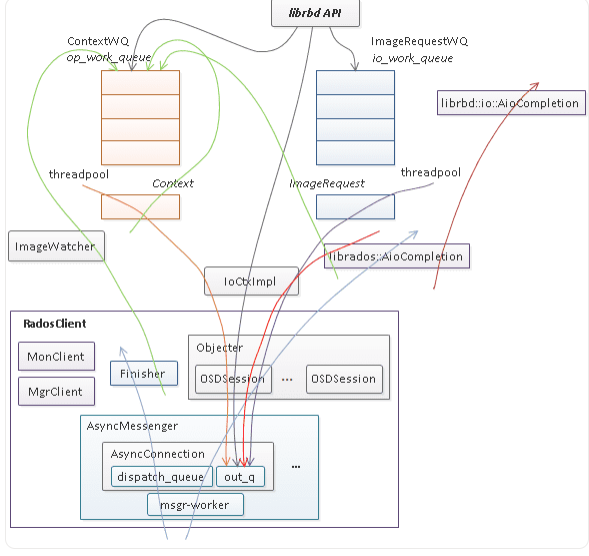
- IO 时序图
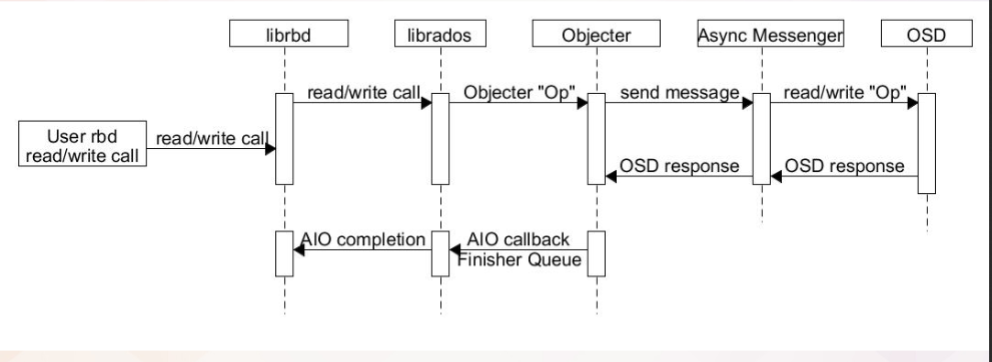
librbd 提供了针对 image 的数据读写和管理操作两种访问接口,其中数据读写请求入
io_work_queue,然后由线程池中的线程将 io 请求以 object 粒度切分并分别调用 rados 层的 aio 接口(IoCtxImpl)下发,当所有的 object 请求完成时,调用 librbd io 回调(librbd::io::AioCompletion)完成用户层的数据 io。而对 image 的管理操作通常需要涉及单个或多个对象的多次访问以及对内部状态的多次更新,其第一次访问将从用户线程调用至 rados 层 aio 接口或更新状态后入op_work_queue队列进行异步调用,当 rados aio 层回调或 Context 完成时再根据实现逻辑调用新的 rados aio 或构造 Context 回调,如此反复,最后调用应用层的回调完成管理操作请求。此外为了支持多客户端共享访问 image,librbd 提供了构建于 rados watch/notify 之上的通知、远程执行以及 exclusive lock 分布式锁机制。每个 librbd 客户端在打开 image 时(以非只读方式打开)都会 watch image 的 header 对象,从远程发往本地客户端的通知消息或者内部的 watch 错误消息会通过 RadosClient 的 Finisher 线程入 op_work_queue 队列进行异步处理。
组成元素
- image 主要由
rbd_header元数据 rados 对象及rbd_data数据 rados 对象组成,随着特性的增加会增加其它一些元数据对象,但 librbd 内部的运行机制并不会有大的变化,一切都以异步 io、事件(请求)驱动为基础。
相关接口声明
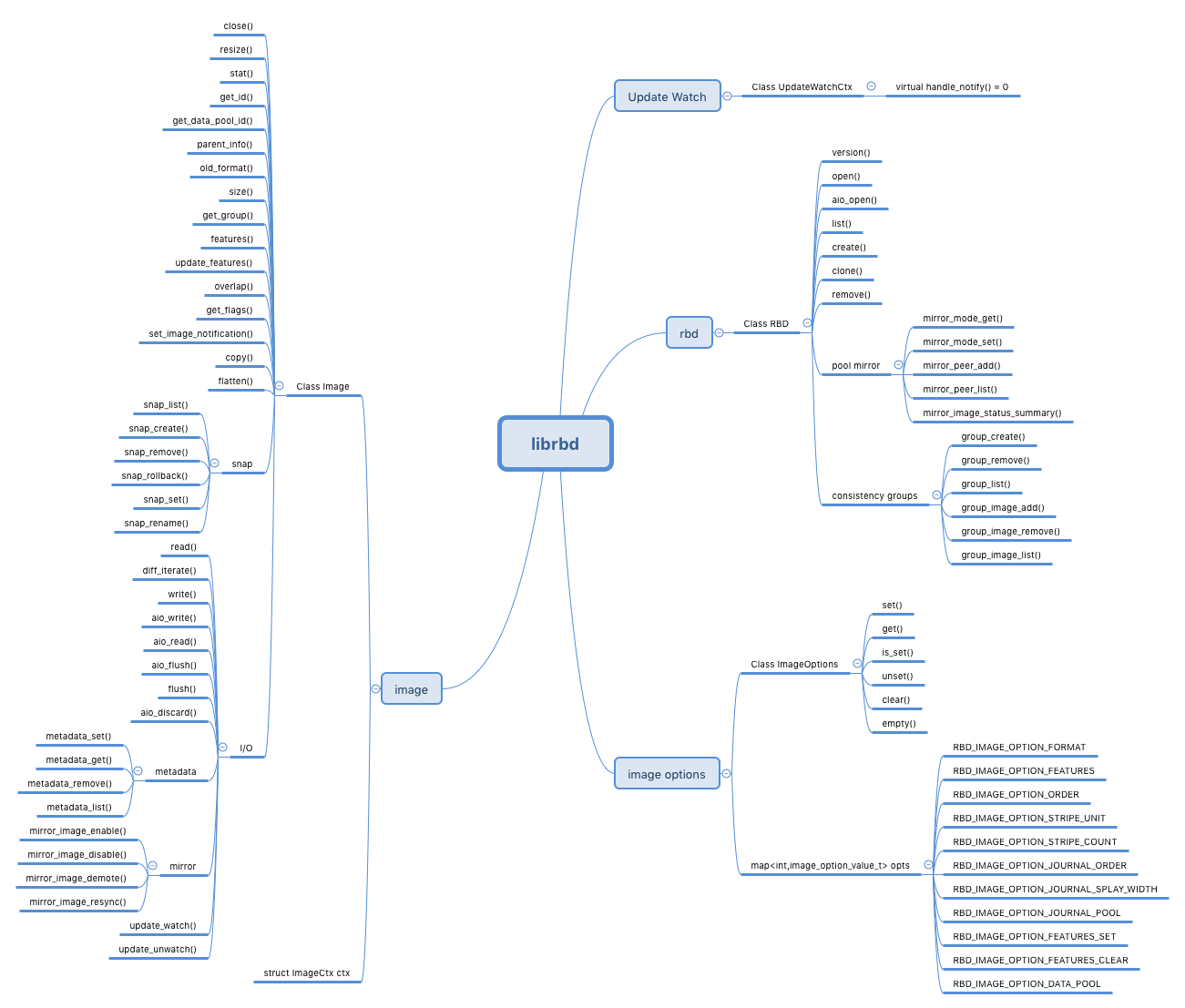
- 此处以 librbd 的 C++ 库 librbd.hpp 为例对 librbd 提供的相关功能 API 进行介绍(除此以外还提供了 C 语言的相关库 librbd.h)
- librbd 提供的接口导图如下:
1 | namespace librbd { // 库在librbd名字空间中 |
class CEPH_RBD_API RBD
- RBD 主要负责 Image 的创建、删除、重命名、克隆映像等操作,包括对存储池的元数据的管理
- 针对部分操作提供异步接口
1 | class CEPH_RBD_API RBD |
class CEPH_RBD_API Image
- Image 类负责镜像的读写(read/write),以及快照相关的操作等等。
- 同时提供了相关异步操作的接口。
1 | class CEPH_RBD_API Image |
具体实现
- librbd.cc 主要实现了 I/O 相关接口 read/write。
- internal.cc 主要实现了定义在头文件中的相关函数接口
Cls
- cls_rbd是Cls的一个扩展模块,Cls允许用户自定义对象的操作接口和实现方法,为用户提供了一种比较直接的接口扩展方式。通过动态链接的形式加入 osd 中,在 osd 上直接执行。
Client
- cls_rbd_client.h/cc 该文件中主要定义了客户端上运行的接口,将函数参数封装后发送给服务端 OSD ,然后做后续处理.
cls_rbd_client.h/cc定义了通过客户端访问osd注册的cls函数的方法。以snapshot_add函数和create_image函数为例,这个函数将参数封装进 bufferlist ,通过 ioctx->exec 方法,把操作发送给osd处理。
1 | void snapshot_add(librados::ObjectWriteOperation *op, snapid_t snap_id, |
Server
- cls_rbd.h/cc 该类中主要定义了服务端上(OSD)执行的函数,响应客户端的请求。在
cls_rbd.cc函数中,对函数进行定义和注册。 - 例如,下面的代码注册了rbd模块,以及
snapshot_add和create函数。
1 | cls_register("rbd", |
- cls_rbd.cc定义了方法在服务端的实现,其一般流程是:从bufferlist将客户端传入的参数解析出来,调用对应的方法实现,然后将结果返回客户端。
1 | /** |
Others

分片 Striper
- Ceph RBD 默认分片到了许多对象上,这些对象最终会存储在 RADOS 中,对 RBD Image 的读写请求会分布在集群中的很多个节点上,从而避免当 RBD Image 特别大或者繁忙的时候,单个节点不会成为瓶颈。
- Ceph RBD 的分片由三个参数控制
- object-size,代码中常常简写为 os,通常为 2 的幂指数,默认的对象大小是4 MB,最小的是4K,最大的是32M
- stripe_unit,代码中常常简写为 su,一个对象中存储了连续该大小的分片。默认和对象大小相等。
- stripe_count,代码中常常简写为 sc,在向 [stripe_count] 对象写入 [stripe_unit] 字节后,循环到初始对象并写入另一个条带,直到对象达到其最大大小。此时,将继续处理下一个 [stripe_count] 对象。
- 分片的组织形式类似于 RAID0,看一个来自官网的 例子。此处只举例一个 Object Set,对象大小在如下图示中即为纵向的一个对象大小,由整数个分片单元组成,而一个分片是指指定 stripe_count 个 stripe_unit,图示中的 stripe_count 即为 5,假设 stripe_unit 为 64KB,那么对应的分片大小即为 320KB,对象大小如果设置为 64GB,那么一个对象对应的就会有 64GB/64KB = 1048576 个 stripe_unit.
1 | _________ _________ _________ _________ _________ |
1 | class Striper { |
- 分片大小对应的数据结构:
1 | struct file_layout_t { |
- 查看分片类对应的实现:ceph/src/osdc/Striper.cc
1 | void Striper::file_to_extents(CephContext *cct, const char *object_format, |
数据 IO
- 主要对应于
ImageCtx::io_work_queue成员变量。librbd::io::ImageRequestWQ派生自ThreadPool::PointerWQ(<= Luminous) / ThreadPool::PointerWQ(>= Mimic)。 - librbd 支持两种类型的 aio,一种是普通的 aio,一种是非阻塞 aio。前者的行为相对简单,直接在用户线程的上下文进行 io 处理,而后者将用户的 io 直接入
io_work_queue队列,然后 io 由队列的工作线程出队并在工作线程上下文进行后续的处理。这两种 aio 的行为由配置参数rbd_non_blocking_aio决定,默认为 true,因此默认为非阻塞 aio,但需要注意的是,即使默认不是非阻塞 aio,在某些场景下 aio 仍然会需要入io_work_queue队列,总结如下:
read
ImageRequestWQ::writes_blocked()为 true,即已调用ImageRequestWQ::block_writes,当前已禁止 write io 下发至 rados 层;ImageRequestWQ::writes_empty()为 false,即前面已经有 write io 入了io_work_queue队列;ImageRequestWQ::require_lock_on_read()为 true,这里的 lock 是指 exclusive lock,表示当前还未拿到,在启用 exclusive lock 特性的前提下,一旦开启克隆 COR (copy on read) 或者启用 journaling 特性,处理 read io 也要求拿锁;
write
ImageRequestWQ::writes_blocked()为 true,即已调用ImageRequestWQ::block_writes,当前已禁止 write io 下发至 rados 层;- 对于 write 而言,并没有类似
ImageRequestWQ::require_lock_on_write的接口,这是因为一旦启用 exclusive lock 特性,在初始化 exclusive lock 时会调用ImageRequestWQ::block_writes(参考 ExclusiveLock::init),直至拿到锁(参考ExclusiveLock::handle_post_acquired_lock),因此增加ImageRequestWQ::require_lock_on_write接口并没有必要。 - 需要注意的是,ImageRequestWQ::block_writes 并不只是简单的设置禁止标志,还需要 flush 已下发的 rados io,即等待所有已下发的 rados io 结束才返回。
- 从上面对 read、write 的分析,似乎
ImageRequestWQ::writes_blocked改成ImageRequestWQ::io_blocked似乎更合理,但实际上这里并没有真的禁止 read io 下发至 rados 层,只是让 read io 先入io_work_queue队列。
TCMU-RBD
1 | static void tcmu_rbd_image_close(struct tcmu_device *dev) |
参考链接
- [1] Ceph RDB 官方文档介绍
- [2] 简书 - ceph rbd:总览
- [3] 掘金 - Ceph介绍及原理架构分享
- [4] CSDN:Ceph学习——Librbd块存储库与RBD读写流程源码分析
- [5] CSDN:Ceph RBD编程接口Librbd(C++) – 映像创建与数据读写
- [6] 腾讯云专栏:大话Ceph系列
- [7] runsisi.com - librbd 内部运行机制
- [8] CSDN:Ceph学习——Librados与Osdc实现源码解析
- [9] CSDN:librbd代码目录解读
- [10] Ceph: RBD 创建镜像过程以及源码分析
- [11] librbd 架构分析